Monitoring
In the Monitoring section, a link to the infrastructure node monitoring application is provided.
Monitoring is achieved through a combination of the following tools:
Telegraf is an open-source agent used for collecting metrics and data from the system.
InfluxDB is a freely distributed time series database (TSDB). All data collected by Telegraf is sent to InfluxDB.
Grafana is a tool for graphical representation of metrics, compatible with the InfluxDB database. It is used for creating indicator panels (dashboards) that display specific metrics over a defined period of time.
When first accessing the Statistics section, you will be redirected to the Grafana login page.
Please consult your administrator to obtain the login and password to access the Grafana dashboard.
The monitoring system login screen
To view the collected metrics, follow these steps:
Select the Dashboards button to open the menu.
Select Browse to access the list of panels.
Select a panel.
Accessing the Panel List from the menu
By default, three sets of dashboards are provided.
Infrastructure monitoring
This set is designed for monitoring configurable infrastructure units such as areas, regions, buildings, groups, etc.
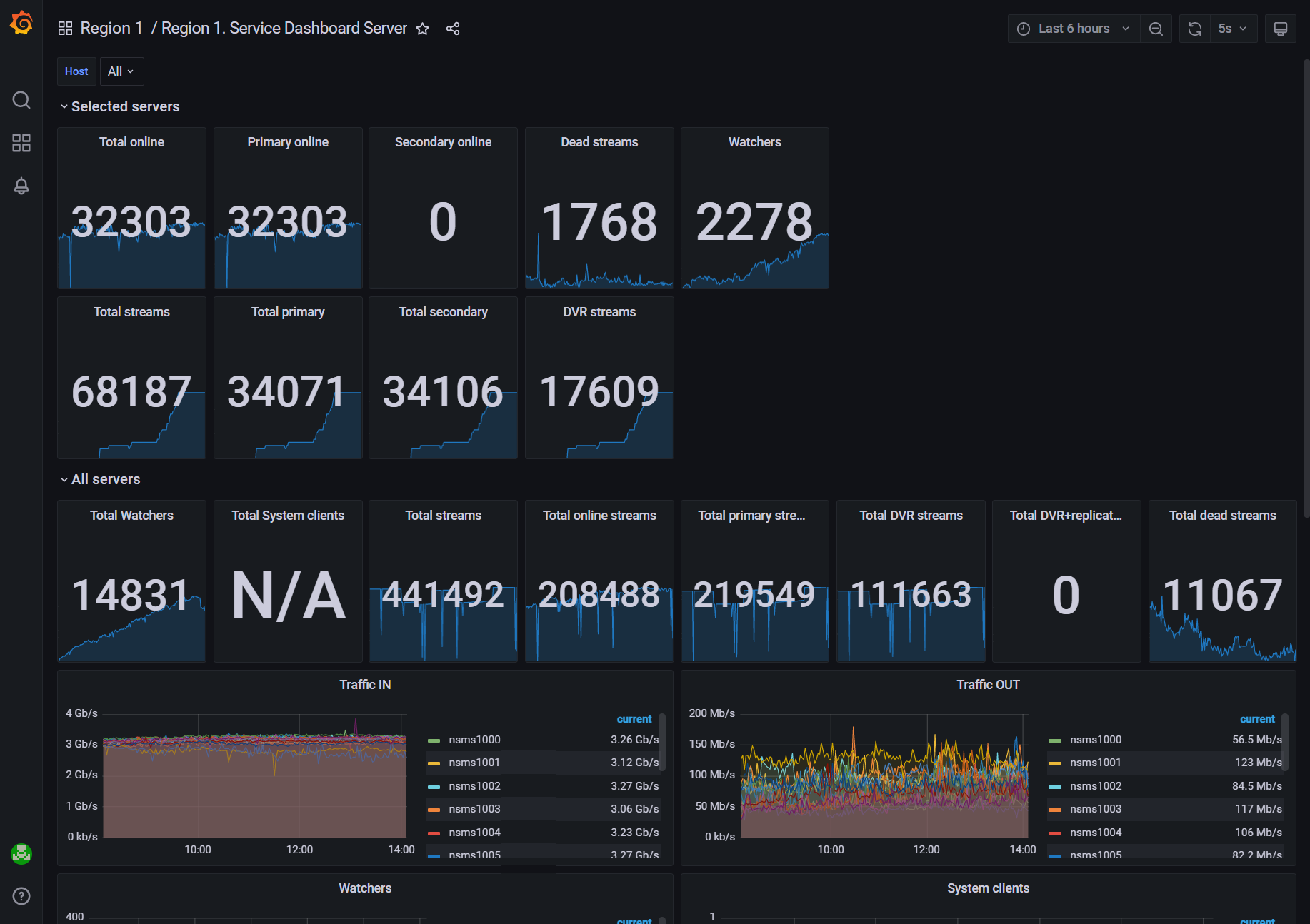
The Service Dashboard Server dashboard
This set includes the following dashboards:
Server: region cluster. Monitors Mediaserver service parameters such as version, CPU load, memory, socket statistics.
Common indicator. Traffic statistics on media servers (overall and per each media server).
Service Dashboard Server. Statistics on cameras, streams, users, traffic, and viewers.
3 days storage usage forecast. It’s a three-day forecast of disk space utilization.
Disks health. Monitors disk errors (HDD and SSD).
System dashboard: region cluster. Monitors server metrics (memory, processes, network, disks, etc.).
Alerts
This set contains dashboards for monitoring and alert rules that are configured for deviations from acceptable values.
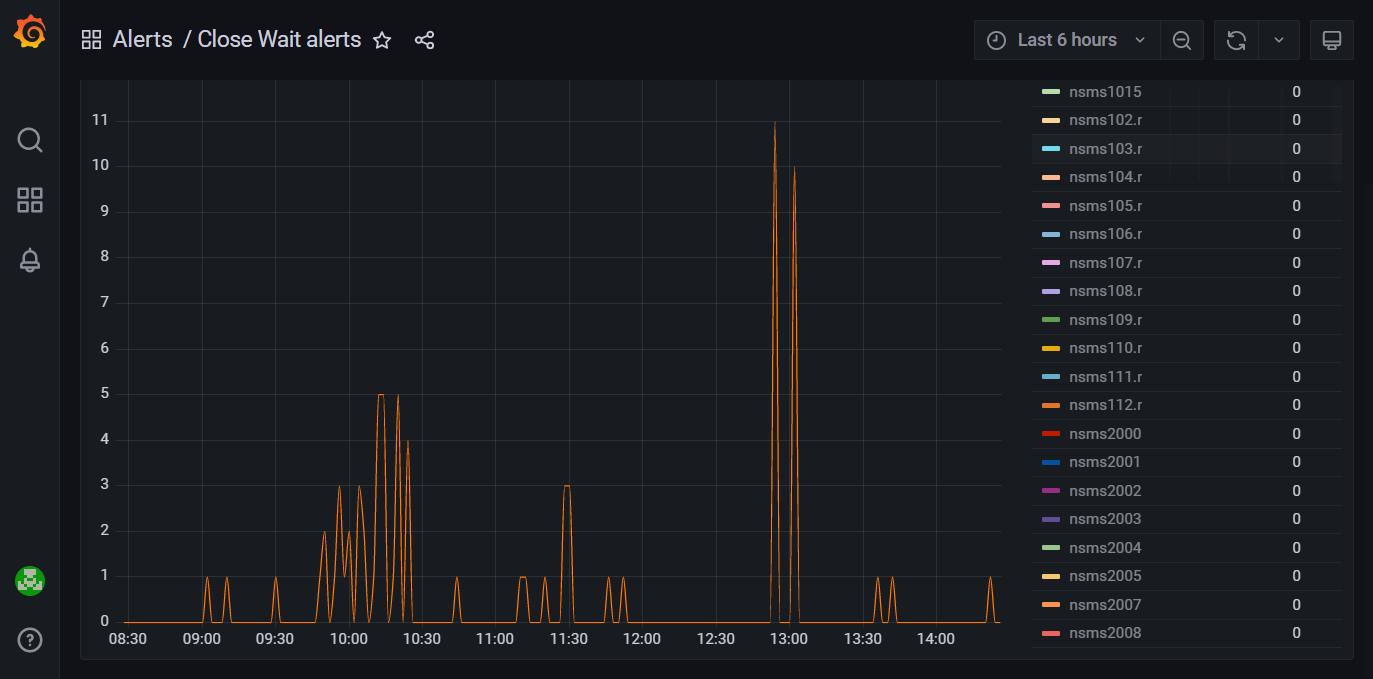
The Close Wait alerts dashboard
Close Wait alerts. Monitors the
close_waitparameter for all media servers and alerts in case of exceeding the threshold value.Disk Usage alerting. Monitors disk space and triggers alerts when usage exceeds a specified threshold.
Service state & input traffic. Monitors incoming server traffic and alerts if it falls below a specified threshold.
Monitoring
This set contains dashboards for monitoring various performance indicators and service status in the Production installation.
The System dashboard dashboard
DHCP. Monitors the DHCP service status and its operational statistics.
NS_APP Monitoring. Monitors CPU and memory usage by resource-intensive processes.
Percona cluster. Monitors the Percona cluster state (a three-node DB cluster) and alerts when an individual node is unavailable.
Supervisor processes monitoring. Monitors processes launched through Supervisor on two App servers.
System dashboard. Monitors server metrics (memory, processes, network, disks, etc.).